


Classes | |
| class | Acrobot |
| Implementation of Acrobot game. More... | |
| class | AggregatedPolicy |
| class | AsyncLearning |
| Wrapper of various asynchronous learning algorithms, e.g. More... | |
| class | CartPole |
| Implementation of Cart Pole task. More... | |
| class | ContinuousDoublePoleCart |
| Implementation of Continuous Double Pole Cart Balancing task. More... | |
| class | ContinuousMountainCar |
| Implementation of Continuous Mountain Car task. More... | |
| class | DoublePoleCart |
| Implementation of Double Pole Cart Balancing task. More... | |
| class | GreedyPolicy |
| Implementation for epsilon greedy policy. More... | |
| class | MountainCar |
| Implementation of Mountain Car task. More... | |
| class | NStepQLearningWorker |
| Forward declaration of NStepQLearningWorker. More... | |
| class | OneStepQLearningWorker |
| Forward declaration of OneStepQLearningWorker. More... | |
| class | OneStepSarsaWorker |
| Forward declaration of OneStepSarsaWorker. More... | |
| class | Pendulum |
| Implementation of Pendulum task. More... | |
| class | PrioritizedReplay |
| Implementation of prioritized experience replay. More... | |
| class | QLearning |
| Implementation of various Q-Learning algorithms, such as DQN, double DQN. More... | |
| class | RandomReplay |
| Implementation of random experience replay. More... | |
| class | RewardClipping |
Interface for clipping the reward to some value between the specified maximum and minimum value (Clipping here is implemented as 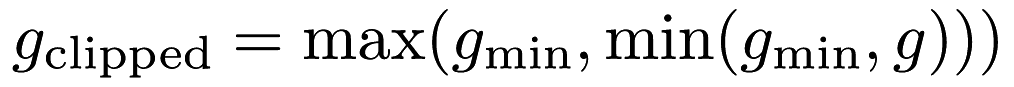 .) More... .) More... | |
| class | SumTree |
| Implementation of SumTree. More... | |
| class | TrainingConfig |
Typedefs | |
template < typename EnvironmentType , typename NetworkType , typename UpdaterType , typename PolicyType > | |
| using | NStepQLearning = AsyncLearning< NStepQLearningWorker< EnvironmentType, NetworkType, UpdaterType, PolicyType >, EnvironmentType, NetworkType, UpdaterType, PolicyType > |
| Convenient typedef for async n step q-learning. More... | |
template < typename EnvironmentType , typename NetworkType , typename UpdaterType , typename PolicyType > | |
| using | OneStepQLearning = AsyncLearning< OneStepQLearningWorker< EnvironmentType, NetworkType, UpdaterType, PolicyType >, EnvironmentType, NetworkType, UpdaterType, PolicyType > |
| Convenient typedef for async one step q-learning. More... | |
template < typename EnvironmentType , typename NetworkType , typename UpdaterType , typename PolicyType > | |
| using | OneStepSarsa = AsyncLearning< OneStepSarsaWorker< EnvironmentType, NetworkType, UpdaterType, PolicyType >, EnvironmentType, NetworkType, UpdaterType, PolicyType > |
| Convenient typedef for async one step Sarsa. More... | |
Typedef Documentation
◆ NStepQLearning
| using NStepQLearning = AsyncLearning<NStepQLearningWorker<EnvironmentType, NetworkType, UpdaterType, PolicyType>, EnvironmentType, NetworkType, UpdaterType, PolicyType> |
Convenient typedef for async n step q-learning.
- Template Parameters
-
EnvironmentType The type of the reinforcement learning task. NetworkType The type of the network model. UpdaterType The type of the optimizer. PolicyType The type of the behavior policy.
Definition at line 233 of file async_learning.hpp.
◆ OneStepQLearning
| using OneStepQLearning = AsyncLearning<OneStepQLearningWorker<EnvironmentType, NetworkType, UpdaterType, PolicyType>, EnvironmentType, NetworkType, UpdaterType, PolicyType> |
Convenient typedef for async one step q-learning.
- Template Parameters
-
EnvironmentType The type of the reinforcement learning task. NetworkType The type of the network model. UpdaterType The type of the optimizer. PolicyType The type of the behavior policy.
Definition at line 197 of file async_learning.hpp.
◆ OneStepSarsa
| using OneStepSarsa = AsyncLearning<OneStepSarsaWorker<EnvironmentType, NetworkType, UpdaterType, PolicyType>, EnvironmentType, NetworkType, UpdaterType, PolicyType> |
Convenient typedef for async one step Sarsa.
- Template Parameters
-
EnvironmentType The type of the reinforcement learning task. NetworkType The type of the network model. UpdaterType The type of the optimizer. PolicyType The type of the behavior policy.
Definition at line 215 of file async_learning.hpp.