|
| class | AdaDelta |
| | AdaDelta is an optimizer that uses two ideas to improve upon the two main drawbacks of the Adagrad method: More...
|
| |
| class | AdaDeltaUpdate |
| | Implementation of the AdaDelta update policy. More...
|
| |
| class | AdaGrad |
| | AdaGrad is a modified version of stochastic gradient descent which performs larger updates for more sparse parameters and smaller updates for less sparse parameters. More...
|
| |
| class | AdaGradUpdate |
| | Implementation of the AdaGrad update policy. More...
|
| |
| class | AdaMaxUpdate |
| | AdaMax is a variant of Adam, an optimizer that computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients.based on the infinity norm as given in the section 7 of the following paper. More...
|
| |
| class | AdamType |
| | Adam is an optimizer that computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients. More...
|
| |
| class | AdamUpdate |
| | Adam is an optimizer that computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients as given in the section 7 of the following paper. More...
|
| |
| class | AdaptiveStepsize |
| | Definition of the adaptive stepize technique, a non-monotonic stepsize scheme that uses curvature estimates to propose new stepsize choices. More...
|
| |
| class | AddDecomposableEvaluate |
| | The AddDecomposableEvaluate mixin class will add a decomposable Evaluate() method if a decomposable EvaluateWithGradient() function exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableEvaluate< FunctionType, HasDecomposableEvaluateWithGradient, true > |
| | Reflect the existing Evaluate(). More...
|
| |
| class | AddDecomposableEvaluate< FunctionType, true, false > |
| | If we have a decomposable EvaluateWithGradient() but not a decomposable Evaluate(), add a decomposable Evaluate() method. More...
|
| |
| class | AddDecomposableEvaluateConst |
| | The AddDecomposableEvaluateConst mixin class will add a decomposable const Evaluate() method if a decomposable const EvaluateWithGradient() function exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableEvaluateConst< FunctionType, HasDecomposableEvaluateWithGradient, true > |
| | Reflect the existing Evaluate(). More...
|
| |
| class | AddDecomposableEvaluateConst< FunctionType, true, false > |
| | If we have a decomposable const EvaluateWithGradient() but not a decomposable const Evaluate(), add a decomposable const Evaluate() method. More...
|
| |
| class | AddDecomposableEvaluateStatic |
| | The AddDecomposableEvaluateStatic mixin class will add a decomposable static Evaluate() method if a decomposable static EvaluateWithGradient() function exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableEvaluateStatic< FunctionType, HasDecomposableEvaluateWithGradient, true > |
| | Reflect the existing Evaluate(). More...
|
| |
| class | AddDecomposableEvaluateStatic< FunctionType, true, false > |
| | If we have a decomposable EvaluateWithGradient() but not a decomposable Evaluate(), add a decomposable Evaluate() method. More...
|
| |
| class | AddDecomposableEvaluateWithGradient |
| | The AddDecomposableEvaluateWithGradient mixin class will add a decomposable EvaluateWithGradient() method if a decomposable Evaluate() method and a decomposable Gradient() method exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableEvaluateWithGradient< FunctionType, false, true, true > |
| | If the FunctionType has EvaluateWithGradient() but not Evaluate(), provide that function. More...
|
| |
| class | AddDecomposableEvaluateWithGradient< FunctionType, HasDecomposableEvaluateGradient, true > |
| | Reflect the existing EvaluateWithGradient(). More...
|
| |
| class | AddDecomposableEvaluateWithGradient< FunctionType, true, false > |
| | If we have a both decomposable Evaluate() and a decomposable Gradient() but not a decomposable EvaluateWithGradient(), add a decomposable EvaluateWithGradient() method. More...
|
| |
| class | AddDecomposableEvaluateWithGradient< FunctionType, true, false, true > |
| | If the FunctionType has EvaluateWithGradient() but not Gradient(), provide that function. More...
|
| |
| class | AddDecomposableEvaluateWithGradient< FunctionType, true, true, false > |
| | If the FunctionType has Evaluate() and Gradient() but not EvaluateWithGradient(), we will provide the latter. More...
|
| |
| class | AddDecomposableEvaluateWithGradientConst |
| | The AddDecomposableEvaluateWithGradientConst mixin class will add a decomposable const EvaluateWithGradient() method if both a decomposable const Evaluate() and a decomposable const Gradient() function exist, or nothing otherwise. More...
|
| |
| class | AddDecomposableEvaluateWithGradientConst< FunctionType, HasDecomposableEvaluateGradient, true > |
| | Reflect the existing EvaluateWithGradient(). More...
|
| |
| class | AddDecomposableEvaluateWithGradientConst< FunctionType, true, false > |
| | If we have both a decomposable const Evaluate() and a decomposable const Gradient() but not a decomposable const EvaluateWithGradient(), add a decomposable const EvaluateWithGradient() method. More...
|
| |
| class | AddDecomposableEvaluateWithGradientStatic |
| | The AddDecomposableEvaluateWithGradientStatic mixin class will add a decomposable static EvaluateWithGradient() method if both a decomposable static Evaluate() and a decomposable static gradient() function exist, or nothing otherwise. More...
|
| |
| class | AddDecomposableEvaluateWithGradientStatic< FunctionType, HasDecomposableEvaluateGradient, true > |
| | Reflect the existing EvaluateWithGradient(). More...
|
| |
| class | AddDecomposableEvaluateWithGradientStatic< FunctionType, true, false > |
| | If we have a decomposable static Evaluate() and a decomposable static Gradient() but not a decomposable static EvaluateWithGradient(), add a decomposable static Gradient() method. More...
|
| |
| class | AddDecomposableGradient |
| | The AddDecomposableGradient mixin class will add a decomposable Gradient() method if a decomposable EvaluateWithGradient() function exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableGradient< FunctionType, HasDecomposableEvaluateWithGradient, true > |
| | Reflect the existing Gradient(). More...
|
| |
| class | AddDecomposableGradient< FunctionType, true, false > |
| | If we have a decomposable EvaluateWithGradient() but not a decomposable Gradient(), add a decomposable Evaluate() method. More...
|
| |
| class | AddDecomposableGradientConst |
| | The AddDecomposableGradientConst mixin class will add a decomposable const Gradient() method if a decomposable const EvaluateWithGradient() function exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableGradientConst< FunctionType, HasDecomposableEvaluateWithGradient, true > |
| | Reflect the existing Gradient(). More...
|
| |
| class | AddDecomposableGradientConst< FunctionType, true, false > |
| | If we have a decomposable const EvaluateWithGradient() but not a decomposable const Gradient(), add a decomposable const Gradient() method. More...
|
| |
| class | AddDecomposableGradientStatic |
| | The AddDecomposableEvaluateStatic mixin class will add a decomposable static Gradient() method if a decomposable static EvaluateWithGradient() function exists, or nothing otherwise. More...
|
| |
| class | AddDecomposableGradientStatic< FunctionType, HasDecomposableEvaluateWithGradient, true > |
| | Reflect the existing Gradient(). More...
|
| |
| class | AddDecomposableGradientStatic< FunctionType, true, false > |
| | If we have a decomposable EvaluateWithGradient() but not a decomposable Gradient(), add a decomposable Gradient() method. More...
|
| |
| class | AddEvaluate |
| | The AddEvaluate mixin class will provide an Evaluate() method if the given FunctionType has EvaluateWithGradient(), or nothing otherwise. More...
|
| |
| class | AddEvaluate< FunctionType, HasEvaluateWithGradient, true > |
| | Reflect the existing Evaluate(). More...
|
| |
| class | AddEvaluate< FunctionType, true, false > |
| | If we have EvaluateWithGradient() but no existing Evaluate(), add an Evaluate() method. More...
|
| |
| class | AddEvaluateConst |
| | The AddEvaluateConst mixin class will provide a const Evaluate() method if the given FunctionType has EvaluateWithGradient() const, or nothing otherwise. More...
|
| |
| class | AddEvaluateConst< FunctionType, HasEvaluateWithGradient, true > |
| | Reflect the existing Evaluate(). More...
|
| |
| class | AddEvaluateConst< FunctionType, true, false > |
| | If we have EvaluateWithGradient() but no existing Evaluate(), add an Evaluate() without a using directive to make the base Evaluate() accessible. More...
|
| |
| class | AddEvaluateStatic |
| | The AddEvaluateStatic mixin class will provide a static Evaluate() method if the given FunctionType has EvaluateWithGradient() static, or nothing otherwise. More...
|
| |
| class | AddEvaluateStatic< FunctionType, HasEvaluateWithGradient, true > |
| | Reflect the existing Evaluate(). More...
|
| |
| class | AddEvaluateStatic< FunctionType, true, false > |
| | If we have EvaluateWithGradient() but no existing Evaluate(), add an Evaluate() without a using directive to make the base Evaluate() accessible. More...
|
| |
| class | AddEvaluateWithGradient |
| | The AddEvaluateWithGradient mixin class will provide an EvaluateWithGradient() method if the given FunctionType has both Evaluate() and Gradient(), or it will provide nothing otherwise. More...
|
| |
| class | AddEvaluateWithGradient< FunctionType, HasEvaluateGradient, true > |
| | Reflect the existing EvaluateWithGradient(). More...
|
| |
| class | AddEvaluateWithGradient< FunctionType, true, false > |
| | If the FunctionType has Evaluate() and Gradient(), provide EvaluateWithGradient(). More...
|
| |
| class | AddEvaluateWithGradientConst |
| | The AddEvaluateWithGradient mixin class will provide an EvaluateWithGradient() const method if the given FunctionType has both Evaluate() const and Gradient() const, or it will provide nothing otherwise. More...
|
| |
| class | AddEvaluateWithGradientConst< FunctionType, HasEvaluateGradient, true > |
| | Reflect the existing EvaluateWithGradient(). More...
|
| |
| class | AddEvaluateWithGradientConst< FunctionType, true, false > |
| | If the FunctionType has Evaluate() const and Gradient() const, provide EvaluateWithGradient() const. More...
|
| |
| class | AddEvaluateWithGradientStatic |
| | The AddEvaluateWithGradientStatic mixin class will provide a static EvaluateWithGradient() method if the given FunctionType has both static Evaluate() and static Gradient(), or it will provide nothing otherwise. More...
|
| |
| class | AddEvaluateWithGradientStatic< FunctionType, HasEvaluateGradient, true > |
| | Reflect the existing EvaluateWithGradient(). More...
|
| |
| class | AddEvaluateWithGradientStatic< FunctionType, true, false > |
| | If the FunctionType has static Evaluate() and static Gradient(), provide static EvaluateWithGradient(). More...
|
| |
| class | AddGradient |
| | The AddGradient mixin class will provide a Gradient() method if the given FunctionType has EvaluateWithGradient(), or nothing otherwise. More...
|
| |
| class | AddGradient< FunctionType, HasEvaluateWithGradient, true > |
| | Reflect the existing Gradient(). More...
|
| |
| class | AddGradient< FunctionType, true, false > |
| | If we have EvaluateWithGradient() but no existing Gradient(), add an Gradient() without a using directive to make the base Gradient() accessible. More...
|
| |
| class | AddGradientConst |
| | The AddGradient mixin class will provide a const Gradient() method if the given FunctionType has EvaluateWithGradient() const, or nothing otherwise. More...
|
| |
| class | AddGradientConst< FunctionType, HasEvaluateWithGradient, true > |
| | Reflect the existing Gradient(). More...
|
| |
| class | AddGradientConst< FunctionType, true, false > |
| | If we have EvaluateWithGradient() but no existing Gradient(), add a Gradient() without a using directive to make the base Gradient() accessible. More...
|
| |
| class | AddGradientStatic |
| | The AddGradient mixin class will provide a static Gradient() method if the given FunctionType has static EvaluateWithGradient(), or nothing otherwise. More...
|
| |
| class | AddGradientStatic< FunctionType, HasEvaluateWithGradient, true > |
| | Reflect the existing Gradient(). More...
|
| |
| class | AddGradientStatic< FunctionType, true, false > |
| | If we have EvaluateWithGradient() but no existing Gradient(), add a Gradient() without a using directive to make the base Gradient() accessible. More...
|
| |
| class | AMSGradUpdate |
| | AMSGrad is an exponential moving average variant which along with having benefits of optimizers like Adam and RMSProp, also guarantees convergence. More...
|
| |
| class | Atoms |
| | Class to hold the information and operations of current atoms in the soluton space. More...
|
| |
| class | AugLagrangian |
| | The AugLagrangian class implements the Augmented Lagrangian method of optimization. More...
|
| |
| class | AugLagrangianFunction |
| | This is a utility class used by AugLagrangian, meant to wrap a LagrangianFunction into a function usable by a simple optimizer like L-BFGS. More...
|
| |
| class | AugLagrangianTestFunction |
| | This function is taken from "Practical Mathematical Optimization" (Snyman), section 5.3.8 ("Application of the Augmented Lagrangian Method"). More...
|
| |
| class | BacktrackingLineSearch |
| | Definition of the backtracking line search algorithm based on the Armijo–Goldstein condition to determine the maximum amount to move along the given search direction. More...
|
| |
| class | BarzilaiBorweinDecay |
| | Barzilai-Borwein decay policy for Stochastic variance reduced gradient (SVRG). More...
|
| |
| class | BigBatchSGD |
| | Big-batch Stochastic Gradient Descent is a technique for minimizing a function which can be expressed as a sum of other functions. More...
|
| |
| class | CMAES |
| | CMA-ES - Covariance Matrix Adaptation Evolution Strategy is s a stochastic search algorithm. More...
|
| |
| class | CNE |
| | Conventional Neural Evolution (CNE) is a class of evolutionary algorithms focused on dealing with fixed topology. More...
|
| |
| class | ConstantStep |
| | Implementation of the ConstantStep stepsize decay policy for parallel SGD. More...
|
| |
| class | ConstrLpBallSolver |
| | LinearConstrSolver for FrankWolfe algorithm. More...
|
| |
| class | ConstrStructGroupSolver |
| | Linear Constrained Solver for FrankWolfe. More...
|
| |
| class | CyclicalDecay |
| | Simulate a new warm-started run/restart once a number of epochs are performed. More...
|
| |
| class | CyclicDescent |
| | Cyclic descent policy for Stochastic Coordinate Descent(SCD). More...
|
| |
| class | ExponentialBackoff |
| | Exponential backoff stepsize reduction policy for parallel SGD. More...
|
| |
| class | ExponentialSchedule |
| | The exponential cooling schedule cools the temperature T at every step according to the equation. More...
|
| |
| class | FrankWolfe |
| | Frank-Wolfe is a technique to minimize a continuously differentiable convex function 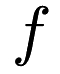 over a compact convex subset over a compact convex subset 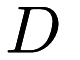 of a vector space. More... of a vector space. More...
|
| |
| class | FullSelection |
| |
| class | FuncSq |
| | Square loss function 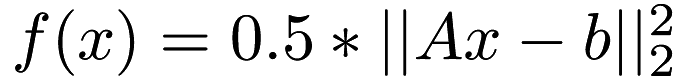 . More... . More...
|
| |
| class | Function |
| | The Function class is a wrapper class for any FunctionType that will add any possible derived methods. More...
|
| |
| class | GockenbachFunction |
| | This function is taken from M. More...
|
| |
| class | GradientClipping |
| | Interface for wrapping around update policies (e.g., VanillaUpdate) and feeding a clipped gradient to them instead of the normal one. More...
|
| |
| class | GradientDescent |
| | Gradient Descent is a technique to minimize a function. More...
|
| |
| class | GreedyDescent |
| | Greedy descent policy for Stochastic Co-ordinate Descent(SCD). More...
|
| |
| class | GridSearch |
| | An optimizer that finds the minimum of a given function by iterating through points on a multidimensional grid. More...
|
| |
| class | GroupLpBall |
| | Implementation of Structured Group. More...
|
| |
| class | IQN |
| | IQN is a technique for minimizing a function which can be expressed as a sum of other functions. More...
|
| |
| class | KatyushaType |
| | Katyusha is a direct, primal-only stochastic gradient method which uses a "negative momentum" on top of Nesterov’s momentum. More...
|
| |
| class | L_BFGS |
| | The generic L-BFGS optimizer, which uses a back-tracking line search algorithm to minimize a function. More...
|
| |
| class | LineSearch |
| | Find the minimum of a function along the line between two points. More...
|
| |
| class | LovaszThetaSDP |
| | This function is the Lovasz-Theta semidefinite program, as implemented in the following paper: More...
|
| |
| class | LRSDP |
| | LRSDP is the implementation of Monteiro and Burer's formulation of low-rank semidefinite programs (LR-SDP). More...
|
| |
| class | LRSDPFunction |
| | The objective function that LRSDP is trying to optimize. More...
|
| |
| class | NadaMaxUpdate |
| | NadaMax is an optimizer that combines the AdaMax and NAG. More...
|
| |
| class | NadamUpdate |
| | Nadam is an optimizer that combines the Adam and NAG optimization strategies. More...
|
| |
| class | NesterovMomentumUpdate |
| | Nesterov Momentum update policy for Stochastic Gradient Descent (SGD). More...
|
| |
| class | NoDecay |
| | Definition of the NoDecay class. More...
|
| |
| class | OptimisticAdamUpdate |
| | OptimisticAdam is an optimizer which implements the Optimistic Adam algorithm which uses Optmistic Mirror Descent with the Adam Optimizer. More...
|
| |
| class | ParallelSGD |
| | An implementation of parallel stochastic gradient descent using the lock-free HOGWILD! approach. More...
|
| |
| class | PrimalDualSolver |
| | Interface to a primal dual interior point solver. More...
|
| |
| class | Proximal |
| | Approximate a vector with another vector on lp ball. More...
|
| |
| class | RandomDescent |
| | Random descent policy for Stochastic Coordinate Descent(SCD). More...
|
| |
| class | RandomSelection |
| |
| class | RMSProp |
| | RMSProp is an optimizer that utilizes the magnitude of recent gradients to normalize the gradients. More...
|
| |
| class | RMSPropUpdate |
| | RMSProp is an optimizer that utilizes the magnitude of recent gradients to normalize the gradients. More...
|
| |
| class | SA |
| | Simulated Annealing is an stochastic optimization algorithm which is able to deliver near-optimal results quickly without knowing the gradient of the function being optimized. More...
|
| |
| class | SARAHPlusUpdate |
| | SARAH+ provides an automatic and adaptive choice of the inner loop size. More...
|
| |
| class | SARAHType |
| | StochAstic Recusive gRadient algoritHm (SARAH). More...
|
| |
| class | SARAHUpdate |
| | Vanilla update policy for SARAH. More...
|
| |
| class | SCD |
| | Stochastic Coordinate descent is a technique for minimizing a function by doing a line search along a single direction at the current point in the iteration. More...
|
| |
| class | SDP |
| | Specify an SDP in primal form. More...
|
| |
| class | SGD |
| | Stochastic Gradient Descent is a technique for minimizing a function which can be expressed as a sum of other functions. More...
|
| |
| class | SGDR |
| | This class is based on Mini-batch Stochastic Gradient Descent class and simulates a new warm-started run/restart once a number of epochs are performed. More...
|
| |
| class | SMORMS3 |
| | SMORMS3 is an optimizer that estimates a safe and optimal distance based on curvature and normalizing the stepsize in the parameter space. More...
|
| |
| class | SMORMS3Update |
| | SMORMS3 is an optimizer that estimates a safe and optimal distance based on curvature and normalizing the stepsize in the parameter space. More...
|
| |
| class | SnapshotEnsembles |
| | Simulate a new warm-started run/restart once a number of epochs are performed. More...
|
| |
| class | SnapshotSGDR |
| | This class is based on Mini-batch Stochastic Gradient Descent class and simulates a new warm-started run/restart once a number of epochs are performed using the Snapshot ensembles technique. More...
|
| |
| class | SPALeRASGD |
| | SPALeRA Stochastic Gradient Descent is a technique for minimizing a function which can be expressed as a sum of other functions. More...
|
| |
| class | SPALeRAStepsize |
| | Definition of the SPALeRA stepize technique, which implementes a change detection mechanism with an agnostic adaptation scheme. More...
|
| |
| class | SVRGType |
| | Stochastic Variance Reduced Gradient is a technique for minimizing a function which can be expressed as a sum of other functions. More...
|
| |
| class | SVRGUpdate |
| | Vanilla update policy for Stochastic variance reduced gradient (SVRG). More...
|
| |
| class | TestFuncFW |
| | Simple test function for classic Frank Wolfe Algorithm: More...
|
| |
| class | UpdateClassic |
| | Use classic rule in the update step for FrankWolfe algorithm. More...
|
| |
| class | UpdateFullCorrection |
| | Full correction approach to update the solution. More...
|
| |
| class | UpdateLineSearch |
| | Use line search in the update step for FrankWolfe algorithm. More...
|
| |
| class | UpdateSpan |
| | Recalculate the optimal solution in the span of all previous solution space, used as update step for FrankWolfe algorithm. More...
|
| |
| class | VanillaUpdate |
| | Vanilla update policy for Stochastic Gradient Descent (SGD). More...
|
| |


