


Stochastic Gradient Descent is a technique for minimizing a function which can be expressed as a sum of other functions. More...
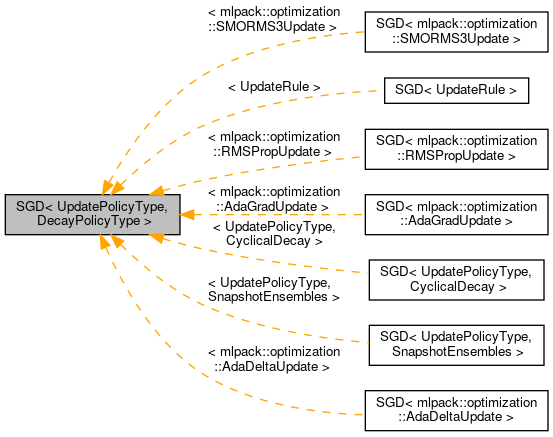
Public Member Functions | |
| SGD (const double stepSize=0.01, const size_t batchSize=32, const size_t maxIterations=100000, const double tolerance=1e-5, const bool shuffle=true, const UpdatePolicyType &updatePolicy=UpdatePolicyType(), const DecayPolicyType &decayPolicy=DecayPolicyType(), const bool resetPolicy=true) | |
| Construct the SGD optimizer with the given function and parameters. More... | |
| size_t | BatchSize () const |
| Get the batch size. More... | |
| size_t & | BatchSize () |
| Modify the batch size. More... | |
| const DecayPolicyType & | DecayPolicy () const |
| Get the step size decay policy. More... | |
| DecayPolicyType & | DecayPolicy () |
| Modify the step size decay policy. More... | |
| size_t | MaxIterations () const |
| Get the maximum number of iterations (0 indicates no limit). More... | |
| size_t & | MaxIterations () |
| Modify the maximum number of iterations (0 indicates no limit). More... | |
template < typename DecomposableFunctionType > | |
| double | Optimize (DecomposableFunctionType &function, arma::mat &iterate) |
| Optimize the given function using stochastic gradient descent. More... | |
| bool | ResetPolicy () const |
| Get whether or not the update policy parameters are reset before Optimize call. More... | |
| bool & | ResetPolicy () |
| Modify whether or not the update policy parameters are reset before Optimize call. More... | |
| bool | Shuffle () const |
| Get whether or not the individual functions are shuffled. More... | |
| bool & | Shuffle () |
| Modify whether or not the individual functions are shuffled. More... | |
| double | StepSize () const |
| Get the step size. More... | |
| double & | StepSize () |
| Modify the step size. More... | |
| double | Tolerance () const |
| Get the tolerance for termination. More... | |
| double & | Tolerance () |
| Modify the tolerance for termination. More... | |
| const UpdatePolicyType & | UpdatePolicy () const |
| Get the update policy. More... | |
| UpdatePolicyType & | UpdatePolicy () |
| Modify the update policy. More... | |
Detailed Description
template<typenameUpdatePolicyType=VanillaUpdate,typenameDecayPolicyType=NoDecay>
class mlpack::optimization::SGD< UpdatePolicyType, DecayPolicyType >
Stochastic Gradient Descent is a technique for minimizing a function which can be expressed as a sum of other functions.
That is, suppose we have
![\[ f(A) = \sum_{i = 0}^{n} f_i(A) \]](form_49.png)
and our task is to minimize 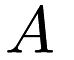 . Stochastic gradient descent iterates over each function
. Stochastic gradient descent iterates over each function 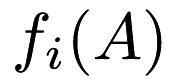 , based on the specified update policy. By default vanilla update policy (see mlpack::optimization::VanillaUpdate) is used. The SGD class supports either scanning through each of the
, based on the specified update policy. By default vanilla update policy (see mlpack::optimization::VanillaUpdate) is used. The SGD class supports either scanning through each of the 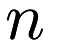 functions
functions 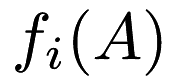 linearly, or in a random sequence. The algorithm continues until
linearly, or in a random sequence. The algorithm continues until 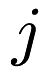 reaches the maximum number of iterations—or when a full sequence of updates through each of the functions produces an improvement within a certain tolerance
reaches the maximum number of iterations—or when a full sequence of updates through each of the functions produces an improvement within a certain tolerance 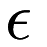 . That is,
. That is,
![\[ | f(A_{j + n}) - f(A_j) | < \epsilon. \]](form_122.png)
The parameter 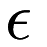 is specified by the tolerance parameter to the constructor;
is specified by the tolerance parameter to the constructor; 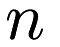 is specified by the maxIterations parameter.
is specified by the maxIterations parameter.
This class is useful for data-dependent functions whose objective function can be expressed as a sum of objective functions operating on an individual point. Then, SGD considers the gradient of the objective function operating on an individual point in its update of .
For SGD to work, a DecomposableFunctionType template parameter is required. This class must implement the following function:
size_t NumFunctions(); double Evaluate(const arma::mat& coordinates, const size_t i, const size_t batchSize); void Gradient(const arma::mat& coordinates, const size_t i, arma::mat& gradient, const size_t batchSize);
NumFunctions() should return the number of functions ( ), and in the other two functions, the parameter i refers to which individual function (or gradient) is being evaluated. So, for the case of a data-dependent function, such as NCA (see mlpack::nca::NCA), NumFunctions() should return the number of points in the dataset, and Evaluate(coordinates, 0) will evaluate the objective function on the first point in the dataset (presumably, the dataset is held internally in the DecomposableFunctionType).
- Template Parameters
-
UpdatePolicyType update policy used by SGD during the iterative update process. By default vanilla update policy (see mlpack::optimization::VanillaUpdate) is used. DecayPolicyType Decay policy used during the iterative update process to adjust the step size. By default the step size isn't going to be adjusted (i.e. NoDecay is used).
Constructor & Destructor Documentation
◆ SGD()
| SGD | ( | const double | stepSize = 0.01, |
| const size_t | batchSize = 32, |
||
| const size_t | maxIterations = 100000, |
||
| const double | tolerance = 1e-5, |
||
| const bool | shuffle = true, |
||
| const UpdatePolicyType & | updatePolicy = UpdatePolicyType(), |
||
| const DecayPolicyType & | decayPolicy = DecayPolicyType(), |
||
| const bool | resetPolicy = true |
||
| ) |
Construct the SGD optimizer with the given function and parameters.
The defaults here are not necessarily good for the given problem, so it is suggested that the values used be tailored to the task at hand. The maximum number of iterations refers to the maximum number of points that are processed (i.e., one iteration equals one point; one iteration does not equal one pass over the dataset).
- Parameters
-
stepSize Step size for each iteration. batchSize Batch size to use for each step. maxIterations Maximum number of iterations allowed (0 means no limit). tolerance Maximum absolute tolerance to terminate algorithm. shuffle If true, the function order is shuffled; otherwise, each function is visited in linear order. updatePolicy Instantiated update policy used to adjust the given parameters. decayPolicy Instantiated decay policy used to adjust the step size. resetPolicy Flag that determines whether update policy parameters are reset before every Optimize call.
Member Function Documentation
◆ BatchSize() [1/2]
|
inline |
Get the batch size.
Definition at line 139 of file sgd.hpp.
Referenced by SGDR< UpdatePolicyType >::BatchSize(), SnapshotSGDR< UpdatePolicyType >::BatchSize(), and AdamType< UpdateRule >::BatchSize().
◆ BatchSize() [2/2]
◆ DecayPolicy() [1/2]
|
inline |
Get the step size decay policy.
Definition at line 171 of file sgd.hpp.
Referenced by SnapshotSGDR< UpdatePolicyType >::Snapshots().
◆ DecayPolicy() [2/2]
|
inline |
◆ MaxIterations() [1/2]
|
inline |
Get the maximum number of iterations (0 indicates no limit).
Definition at line 144 of file sgd.hpp.
Referenced by SGDR< UpdatePolicyType >::MaxIterations(), SnapshotSGDR< UpdatePolicyType >::MaxIterations(), and AdamType< UpdateRule >::MaxIterations().
◆ MaxIterations() [2/2]
|
inline |
◆ Optimize()
| double Optimize | ( | DecomposableFunctionType & | function, |
| arma::mat & | iterate | ||
| ) |
Optimize the given function using stochastic gradient descent.
The given starting point will be modified to store the finishing point of the algorithm, and the final objective value is returned.
- Template Parameters
-
DecomposableFunctionType Type of the function to be optimized.
- Parameters
-
function Function to optimize. iterate Starting point (will be modified).
- Returns
- Objective value of the final point.
Referenced by AdamType< UpdateRule >::Optimize().
◆ ResetPolicy() [1/2]
|
inline |
◆ ResetPolicy() [2/2]
|
inline |
◆ Shuffle() [1/2]
|
inline |
Get whether or not the individual functions are shuffled.
Definition at line 154 of file sgd.hpp.
Referenced by SGDR< UpdatePolicyType >::Shuffle(), SnapshotSGDR< UpdatePolicyType >::Shuffle(), and AdamType< UpdateRule >::Shuffle().
◆ Shuffle() [2/2]
|
inline |
◆ StepSize() [1/2]
|
inline |
Get the step size.
Definition at line 134 of file sgd.hpp.
Referenced by SGDR< UpdatePolicyType >::StepSize(), SnapshotSGDR< UpdatePolicyType >::StepSize(), and AdamType< UpdateRule >::StepSize().
◆ StepSize() [2/2]
◆ Tolerance() [1/2]
|
inline |
Get the tolerance for termination.
Definition at line 149 of file sgd.hpp.
Referenced by SGDR< UpdatePolicyType >::Tolerance(), SnapshotSGDR< UpdatePolicyType >::Tolerance(), and AdamType< UpdateRule >::Tolerance().
◆ Tolerance() [2/2]
|
inline |
◆ UpdatePolicy() [1/2]
|
inline |
Get the update policy.
Definition at line 166 of file sgd.hpp.
Referenced by AdamType< UpdateRule >::Beta1(), AdamType< UpdateRule >::Beta2(), AdamType< UpdateRule >::Epsilon(), SGDR< UpdatePolicyType >::UpdatePolicy(), and SnapshotSGDR< UpdatePolicyType >::UpdatePolicy().
◆ UpdatePolicy() [2/2]
|
inline |
The documentation for this class was generated from the following file:
- src/mlpack/core/optimizers/sgd/sgd.hpp