


Adam is an optimizer that computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients. More...
Public Member Functions | |
| AdamType (const double stepSize=0.001, const size_t batchSize=32, const double beta1=0.9, const double beta2=0.999, const double eps=1e-8, const size_t maxIterations=100000, const double tolerance=1e-5, const bool shuffle=true) | |
| Construct the Adam optimizer with the given function and parameters. More... | |
| size_t | BatchSize () const |
| Get the batch size. More... | |
| size_t & | BatchSize () |
| Modify the batch size. More... | |
| double | Beta1 () const |
| Get the smoothing parameter. More... | |
| double & | Beta1 () |
| Modify the smoothing parameter. More... | |
| double | Beta2 () const |
| Get the second moment coefficient. More... | |
| double & | Beta2 () |
| Modify the second moment coefficient. More... | |
| double | Epsilon () const |
| Get the value used to initialise the mean squared gradient parameter. More... | |
| double & | Epsilon () |
| Modify the value used to initialise the mean squared gradient parameter. More... | |
| size_t | MaxIterations () const |
| Get the maximum number of iterations (0 indicates no limit). More... | |
| size_t & | MaxIterations () |
| Modify the maximum number of iterations (0 indicates no limit). More... | |
template < typename DecomposableFunctionType > | |
| double | Optimize (DecomposableFunctionType &function, arma::mat &iterate) |
| Optimize the given function using Adam. More... | |
| bool | Shuffle () const |
| Get whether or not the individual functions are shuffled. More... | |
| bool & | Shuffle () |
| Modify whether or not the individual functions are shuffled. More... | |
| double | StepSize () const |
| Get the step size. More... | |
| double & | StepSize () |
| Modify the step size. More... | |
| double | Tolerance () const |
| Get the tolerance for termination. More... | |
| double & | Tolerance () |
| Modify the tolerance for termination. More... | |
Detailed Description
template<typenameUpdateRule=AdamUpdate>
class mlpack::optimization::AdamType< UpdateRule >
Adam is an optimizer that computes individual adaptive learning rates for different parameters from estimates of first and second moments of the gradients.
AdaMax is a variant of Adam based on the infinity norm as given in the section 7 of the following paper. Nadam is an optimizer that combines the Adam and NAG. NadaMax is an variant of Nadam based on Infinity form.
For more information, see the following.
For Adam, AdaMax, AMSGrad, Nadam and NadaMax to work, a DecomposableFunctionType template parameter is required. This class must implement the following function:
size_t NumFunctions(); double Evaluate(const arma::mat& coordinates, const size_t i, const size_t batchSize); void Gradient(const arma::mat& coordinates, const size_t i, arma::mat& gradient, const size_t batchSize);
NumFunctions() should return the number of functions ( 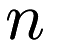 ), and in the other two functions, the parameter i refers to which individual function (or gradient) is being evaluated. So, for the case of a data-dependent function, such as NCA (see mlpack::nca::NCA), NumFunctions() should return the number of points in the dataset, and Evaluate(coordinates, 0) will evaluate the objective function on the first point in the dataset (presumably, the dataset is held internally in the DecomposableFunctionType).
), and in the other two functions, the parameter i refers to which individual function (or gradient) is being evaluated. So, for the case of a data-dependent function, such as NCA (see mlpack::nca::NCA), NumFunctions() should return the number of points in the dataset, and Evaluate(coordinates, 0) will evaluate the objective function on the first point in the dataset (presumably, the dataset is held internally in the DecomposableFunctionType).
- Template Parameters
-
UpdateRule Adam optimizer update rule to be used.
Constructor & Destructor Documentation
◆ AdamType()
| AdamType | ( | const double | stepSize = 0.001, |
| const size_t | batchSize = 32, |
||
| const double | beta1 = 0.9, |
||
| const double | beta2 = 0.999, |
||
| const double | eps = 1e-8, |
||
| const size_t | maxIterations = 100000, |
||
| const double | tolerance = 1e-5, |
||
| const bool | shuffle = true |
||
| ) |
Construct the Adam optimizer with the given function and parameters.
The defaults here are not necessarily good for the given problem, so it is suggested that the values used be tailored to the task at hand. The maximum number of iterations refers to the maximum number of points that are processed (i.e., one iteration equals one point; one iteration does not equal one pass over the dataset).
- Parameters
-
stepSize Step size for each iteration. batchSize Number of points to process in a single step. beta1 Exponential decay rate for the first moment estimates. beta2 Exponential decay rate for the weighted infinity norm estimates. eps Value used to initialise the mean squared gradient parameter. maxIterations Maximum number of iterations allowed (0 means no limit). tolerance Maximum absolute tolerance to terminate algorithm. shuffle If true, the function order is shuffled; otherwise, each function is visited in linear order.
Member Function Documentation
◆ BatchSize() [1/2]
|
inline |
Get the batch size.
Definition at line 141 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::BatchSize().
◆ BatchSize() [2/2]
|
inline |
Modify the batch size.
Definition at line 143 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::BatchSize().
◆ Beta1() [1/2]
|
inline |
Get the smoothing parameter.
Definition at line 146 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::UpdatePolicy().
◆ Beta1() [2/2]
|
inline |
Modify the smoothing parameter.
Definition at line 148 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::UpdatePolicy().
◆ Beta2() [1/2]
|
inline |
Get the second moment coefficient.
Definition at line 151 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::UpdatePolicy().
◆ Beta2() [2/2]
|
inline |
Modify the second moment coefficient.
Definition at line 153 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::UpdatePolicy().
◆ Epsilon() [1/2]
|
inline |
Get the value used to initialise the mean squared gradient parameter.
Definition at line 156 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::UpdatePolicy().
◆ Epsilon() [2/2]
|
inline |
Modify the value used to initialise the mean squared gradient parameter.
Definition at line 158 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::UpdatePolicy().
◆ MaxIterations() [1/2]
|
inline |
Get the maximum number of iterations (0 indicates no limit).
Definition at line 161 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::MaxIterations().
◆ MaxIterations() [2/2]
|
inline |
Modify the maximum number of iterations (0 indicates no limit).
Definition at line 163 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::MaxIterations().
◆ Optimize()
|
inline |
Optimize the given function using Adam.
The given starting point will be modified to store the finishing point of the algorithm, and the final objective value is returned.
- Template Parameters
-
DecomposableFunctionType Type of the function to optimize.
- Parameters
-
function Function to optimize. iterate Starting point (will be modified).
- Returns
- Objective value of the final point.
Definition at line 130 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::Optimize().
◆ Shuffle() [1/2]
|
inline |
Get whether or not the individual functions are shuffled.
Definition at line 171 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::Shuffle().
◆ Shuffle() [2/2]
|
inline |
Modify whether or not the individual functions are shuffled.
Definition at line 173 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::Shuffle().
◆ StepSize() [1/2]
|
inline |
Get the step size.
Definition at line 136 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::StepSize().
◆ StepSize() [2/2]
|
inline |
Modify the step size.
Definition at line 138 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::StepSize().
◆ Tolerance() [1/2]
|
inline |
Get the tolerance for termination.
Definition at line 166 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::Tolerance().
◆ Tolerance() [2/2]
|
inline |
Modify the tolerance for termination.
Definition at line 168 of file adam.hpp.
References SGD< UpdatePolicyType, DecayPolicyType >::Tolerance().
The documentation for this class was generated from the following file:
- src/mlpack/core/optimizers/adam/adam.hpp